

Adi Singh
on 25 June 2020
Open source holds the key to autonomous vehicles
A growing number of car companies have made their autonomous vehicle (AV) datasets public in recent years.
Daimler fueled the trend by making its Cityscapes dataset freely available in 2016. Baidu and Aptiv respectively shared the ApolloScapes and nuScenes datasets in 2018. Lyft, Waymo and Argo followed suit in 2019. And more recently, automotive juggernauts Ford and Audi released datasets from their AV research programs to the public.
Given the potential of self-driving cars to considerably disrupt transportation as we know it, it is worth taking a moment to explore what has motivated these automotive players — otherwise fiercely protective of their intellectual property — to openly share their precious AV datasets with each other and with the wider world.
The idea of AV datasets
AV prototypes come with a bunch of integrated sensors. Cameras, lidars, radars, sonars, GPS, IMUs, thermometers, hygrometers, you name it. Each of these sensors specialises in gathering one specific kind of information about the car’s environment.

Now imagine a fleet of such prototypes driven through different environments under varying traffic, weather and lighting conditions, all the while recording observations from its suite of sensors. The result is an abundant amount of raw data.
Prime up this data through scaling, normalising and removing corrupt values, put it all in one coherent collection, and what you are left with is a nifty AV dataset. The idea of such a dataset is to gather as much information as possible about real world conditions that a self-driving car could find itself in. Why? We’ll get to that in a moment.
For now, let’s talk about data enrichment. Once the dataset is primed, one can go a step further and also label this data with attributes defining the objects perceived by the car. This provides the ground truth for an observation.

Now a program trying to crunch sensor data and find patterns in it can confirm what it is actually looking at. Kind of like a puzzle that has the correct answers at the end of the book. This renders an AV dataset incredibly useful for machine learning tasks.
The importance of datasets
Simply put, datasets are important because AVs rely heavily on machine learning algorithms, and machine learning (ML) in turn relies heavily on observation data.
Let’s unpack that a little.
ML is a branch of programming that deals with building systems that can automatically learn and improve from experience. That is, they can carry out their tasks without explicitly being programmed to handle individual events occurring in the process.
This is crucial for applications where a system can be exposed to virtually an infinite number of scenarios, like a car driving in everyday life. It is impossible to account for every single case that this car may encounter, so we need a mechanism to have the car make decisions about new scenarios based on prior experience. That is the crux of ML.
But where does its experience come from? How does a machine learn?

Enter, datasets.
By examining field data, ML algorithms can deduce patterns in a system and continue fine tuning their behaviour until they demonstrate optimal results across a diverse set of use-cases.
The more data an algorithm crunches, the more it learns, and the better it enables an AV to correctly respond to its environment. Like when to turn, when to stop, when to drive forward and when to give way to other vehicles.
Trained on the right datasets, ML algorithms can be extremely potent in handling even the most unforeseen of circumstances. Stanford professor Andrew Ng famously emphasised this relationship in his lecture series on machine learning: “It’s not who has the best algorithm that wins. It’s who has the most data.”
Which begs the question: If data is indeed the winning factor, why in the world would automotive companies just give away their datasets to the public for free?
The hype machine sputters
To understand this, we must first recognise that AV technology has fallen far short of all the hype and attention it had garnered over the last decade.
Nissan no longer plans to bring its promised driverless vehicle to market this year. Volvo never deployed its much touted fleet of 100 self-driving cars. GM’s ambitions for mass-producing vehicles without steering wheels or pedals are yet to be realised. And I doubt Tesla will have a million robotaxis on the streets by the end of 2020. Even Ford admitted that this technology is “way in the future”, despite having previously announced its own robotaxi rollout by 2021.
As the hype machine sputters, automakers have been left to reckon with the real challenges of developing a practical AV solution. It turns out that building a computer that matches the incredibly nuanced cognitive decisions we make each time we take the driver’s seat is an enormous challenge.
And car companies are slowly realising the limitations of their own resources in tackling these challenges alone.

At this point, what can automotive companies do to make meaningful advancements in AV technology?
A plausible answer lies in open source.
Open source to the rescue
In The Wealth of Networks, Yochai Benkler describes the notion of open source as a mode of production that is “based on sharing resources and outputs among widely distributed, loosely connected individuals who cooperate with each other without relying on either market signals or managerial commands”.
AV companies have spent millions of dollars and thousands of man-hours in accumulating several petabytes of field data. At this scale, it is virtually impossible for a single team to sift through all this data and gainfully apply it to any practical application. Even ignoring the manpower involved, the sheer amount of computing resources that need to execute even the most basic ML techniques on such data exceeds the capacity of a single organisation.

On the other hand, sharing these massive datasets with the public allows individual developers and smaller teams from all over the world to target specific problems which they can attempt to solve with a subset of the data. They can independently work on constructing new algorithms, enhance existing ML models and in general make progress towards addressing key problems in AV technology, all without the extra burden of collecting, cleaning and priming their own datasets.
This is especially important because not many teams out there have the ability to gather the kind of high quality experimental data that automotive outfits are able to collect at scale. By releasing their AV datasets, companies are essentially leveling the playing field. A developer sitting in his garage now has the same opportunity to create the next groundbreaking AV algorithm as an R&D engineer working in a well-funded lab.
Open datasets thereby lower the barriers to innovation. They accelerate technology development. Like any work in the open source community, they set up a framework that prioritises mutual advancement over individual copyright.

Moreover, without well-primed datasets, researchers cannot reasonably be expected to achieve the breakthroughs that are crucial to commercial success in this cutting-edge field. In fact, the criticality of a good dataset to ML research — and by proxy, to AV technology — is tastefully expressed by Google’s adage “Garbage in, garbage out”. The usefulness of an ML model is only as good as the dataset it has been trained on. So high-quality data is needed to create software that can reliably teach autonomous vehicles how to interact with their environments.
Shared datasets also allow engineers from different companies to collaborate on the same data — or, being in the public domain, even combine their individual datasets — to solve problems that are pertinent to both parties. With a common dataset as a shared foundation, teams at different locations and belonging to different organisations can easily replicate results and share code to further refine programs, all the while inching towards greater levels of autonomy.
Democratising AV development through shared datasets benefits the entire community, and a rising tide lifts all boats.
Harnessing the power of open source
Since open source projects are non-proprietary, researchers and developers ultimately share their findings, solutions, and new knowledge back with the community. Even with their raw field data made public, companies can retain competitive advantage by improving their AV technology based on contributions from open source and supporting it commercially. Thus, the upfront investment that auto companies make in collecting AV datasets eventually pays off when new breakthroughs from the community are integrated back into the companies’ products.
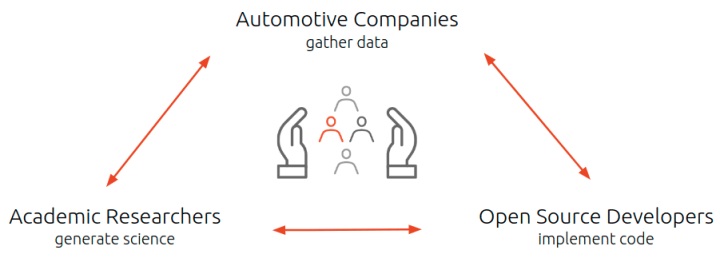
In the true spirit of open source, a symbiotic relationship is established from sharing AV datasets with the public. Researchers gain recognition for their novel insights. Developers build an industry repute for contributions to open source projects. And companies can integrate these new advancements into their own products, thus strengthening their portfolio and bringing new features to their customers faster.
By allowing more people to contribute to the field, car companies can harness the economics of open source and benefit from faster software cycles, more reliable codebases, and volunteer help from some of the brightest minds in the world.
Automotive companies are beginning to understand this, and the industry will greatly benefit if this trend becomes the default.
To find out how Canonical can help with your automotive project, get in touch with us today.


